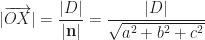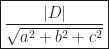(Continued from https://mathtuition88.com/2015/06/25/the-groupoid-properties-of-operation-on-path-homotopy-classes-proof/)
Earlier we have proved the properties (2) Right and left identities, (3) Inverse, leaving us with (1) Associativity to prove.
For this proof, it will be convenient to describe the product f*g in the language of positive linear maps.
First we will need to define what is a positive linear map. We will elaborate more on this since Munkres’ books only discusses it briefly.
Definition: If [a,b] and [c,d] are two intervals in 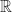 , there is a unique map
, there is a unique map ![p:[a,b]\to [c.d]](https://s0.wp.com/latex.php?latex=p%3A%5Ba%2Cb%5D%5Cto+%5Bc.d%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) of the form p(x)=mx+k that maps a to c and b to d. This is called the positive linear map of [a,b] to [c,d] because its graph is a straight line with positive slope.
of the form p(x)=mx+k that maps a to c and b to d. This is called the positive linear map of [a,b] to [c,d] because its graph is a straight line with positive slope.
Why is it a positive slope? (Not mentioned in the book) It turns out to be because we have:
p(a) = ma+k=c
p(b) = mb+k=d
Hence, d-c = mb-ma = m(b-a)
Thus, m=(d-c)/(b-a), which is positive since d-c and b-a are all positive quantities.
Note that the inverse of a positive linear map is also a positive linear map, and the composite of two such maps is also a positive linear map.
Now, we can show that the product f*g can be described as follows: On [0,1/2], it is the positive linear map of [0,1/2] to [0,1], followed by f; and on [1/2,1] it equals the positive linear map of [1/2,1] to [0,1], followed by g.
Let’s see why this is true. The positive linear map of [0,1/2] to [0,1] is p(x)=2x. fp(x) = f(2x).
The positive linear map of [1/2,1] to [0,1] is p(x)=2x-1. gp(x)=g(2x-1).
If we look back at the earlier definition of f*g, that is precisely it!
Now, given paths, f, g, and h in X, the products f*(g*h) and (f*g)*h are defined if and only if f(1)=g(0) and g(1)=h(0), i.e. the end point of f = start point of g, and the end point of g = start point of h. If we assume that these two conditions hold, we can also define a triple product of the paths f, g, and h as follows:
Choose points a and b of I so that 0<a<b<1. Define a path  in X as follows: On [0,a] it equals the positive linear map of [0,a] to I=[0,1] followed by f; on [a,b] it equals the positive linear map of [a,b] to I followed by g; on [b,1] it equals the positive linear map of [b,1] to I followed by h. This path depends on the choice of the values of a and b, but its path-homotopy class turns out to be independent of a and b.
in X as follows: On [0,a] it equals the positive linear map of [0,a] to I=[0,1] followed by f; on [a,b] it equals the positive linear map of [a,b] to I followed by g; on [b,1] it equals the positive linear map of [b,1] to I followed by h. This path depends on the choice of the values of a and b, but its path-homotopy class turns out to be independent of a and b.
We can show that if c and d are another pair of points of I with 0<c<d<1, then  is path homotopic to .
is path homotopic to .
Let 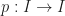 be the map whose graph is pictured in Figure 51.9 (taken from Munkre’s Book)
be the map whose graph is pictured in Figure 51.9 (taken from Munkre’s Book)

On the intervals [0,a], [a,b], [b,1], it equals the positive linear maps of these intervals onto [0,c],[c,d],[d,1] respectively. It follows that  . Let’s see why this is so.
. Let’s see why this is so.
On [0,a]  is the positive linear map of [0,a] to [0,c], followed by the positive linear map of [0,c] to I, followed by f. This equals the positive linear map of [0,a] to I, followed by f, which is precisely . Similar logic holds for the intervals [a,b] and [b,1].
is the positive linear map of [0,a] to [0,c], followed by the positive linear map of [0,c] to I, followed by f. This equals the positive linear map of [0,a] to I, followed by f, which is precisely . Similar logic holds for the intervals [a,b] and [b,1].
 is a path in I from 0 to 1, and so is the identity map
is a path in I from 0 to 1, and so is the identity map  . Since I is convex, there is a path homotopy P in I between p and i. Then,
. Since I is convex, there is a path homotopy P in I between p and i. Then,  is a path homotopy in X between and
is a path homotopy in X between and 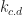 .
.
Now the question many will be asking is: What has this got to do with associativity. According to the author Munkres, “a great deal”! We check that the product 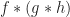 is exactly the triple product in the case where
is exactly the triple product in the case where  and
and  .
.
By definition,
![(g*h)(s)=\begin{cases} g(2s)\ &\text{for }s\in [0,\frac{1}{2}]\\ h(2s-1)\ &\text{for }s\in [\frac{1}{2},1] \end{cases}](https://s0.wp.com/latex.php?latex=%28g%2Ah%29%28s%29%3D%5Cbegin%7Bcases%7D++++g%282s%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B0%2C%5Cfrac%7B1%7D%7B2%7D%5D%5C%5C++++h%282s-1%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B%5Cfrac%7B1%7D%7B2%7D%2C1%5D++++%5Cend%7Bcases%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Thus, ![f*(g*h)(s)=\begin{cases} f(2s)\ &\text{for }s\in [0,\frac{1}{2}]\\ (g*h)(2s-1)\ &\text{for }s\in [\frac{1}{2},1] \end{cases} =\begin{cases} f(2s)\ &\text{for }s\in [0,\frac{1}{2}]\\ g(4s-2)\ &\text{for }s\in [\frac{1}{2},\frac{3}{4}]\\ h(4s-3) &\text{for }s\in [\frac{3}{4},1] \end{cases}](https://s0.wp.com/latex.php?latex=f%2A%28g%2Ah%29%28s%29%3D%5Cbegin%7Bcases%7D++++f%282s%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B0%2C%5Cfrac%7B1%7D%7B2%7D%5D%5C%5C++++%28g%2Ah%29%282s-1%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B%5Cfrac%7B1%7D%7B2%7D%2C1%5D++++%5Cend%7Bcases%7D++++%3D%5Cbegin%7Bcases%7D++++f%282s%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B0%2C%5Cfrac%7B1%7D%7B2%7D%5D%5C%5C++++g%284s-2%29%5C+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B%5Cfrac%7B1%7D%7B2%7D%2C%5Cfrac%7B3%7D%7B4%7D%5D%5C%5C++++h%284s-3%29+%26%5Ctext%7Bfor+%7Ds%5Cin+%5B%5Cfrac%7B3%7D%7B4%7D%2C1%5D++++%5Cend%7Bcases%7D++++&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We can also check in a very similar way that  when c=1/4 and d=1/2. Thus, the these two products are path homotopic, and we have finally proven the associativity of *.
when c=1/4 and d=1/2. Thus, the these two products are path homotopic, and we have finally proven the associativity of *.
Reference:


Topology (2nd Economy Edition)


![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)




![x\in [a,b]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Ba%2Cb%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
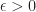
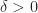


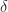

![g:[0,1]\times [0,1]\to [0,1]](https://s0.wp.com/latex.php?latex=g%3A%5B0%2C1%5D%5Ctimes+%5B0%2C1%5D%5Cto+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


![f:[0,1]\to\mathbb{R}](https://s0.wp.com/latex.php?latex=f%3A%5B0%2C1%5D%5Cto%5Cmathbb%7BR%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

![x\in [0,1]](https://s0.wp.com/latex.php?latex=x%5Cin+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)











![\mathbb{Z}[i]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bi%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) are the set of complex numbers of the form
are the set of complex numbers of the form  , with
, with  integers. Originally discovered and studied by Gauss, the Gaussian Integers are useful in number theory, for instance they can be used to prove that
integers. Originally discovered and studied by Gauss, the Gaussian Integers are useful in number theory, for instance they can be used to prove that 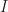 is any nonzero ideal in
is any nonzero ideal in ![\mathbb{Z}[i]/I](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5Bi%5D%2FI&bg=ffffff&fg=1a1a1a&s=0&c=20201002) is finite.
is finite. for some nonzero
for some nonzero ![\alpha\in\mathbb{Z}[i]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5Cmathbb%7BZ%7D%5Bi%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . Let
. Let ![\beta\in\mathbb{Z}[i]](https://s0.wp.com/latex.php?latex=%5Cbeta%5Cin%5Cmathbb%7BZ%7D%5Bi%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. with
with 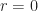 or
or  . We also note that
. We also note that  .
.![\begin{aligned}\mathbb{Z}[i]/I&=\{\beta+I\mid\beta\in\mathbb{Z}[i]\}\\ &=\{r+I\mid r\in\mathbb{Z}[i],N(r)<N(\alpha)\} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb%7BZ%7D%5Bi%5D%2FI%26%3D%5C%7B%5Cbeta%2BI%5Cmid%5Cbeta%5Cin%5Cmathbb%7BZ%7D%5Bi%5D%5C%7D%5C%5C++++%26%3D%5C%7Br%2BI%5Cmid+r%5Cin%5Cmathbb%7BZ%7D%5Bi%5D%2CN%28r%29%3CN%28%5Calpha%29%5C%7D++++%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.![r\in\mathbb{Z}[i]](https://s0.wp.com/latex.php?latex=r%5Cin%5Cmathbb%7BZ%7D%5Bi%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) with
with  of an arbitrary collection of path-connected spaces
of an arbitrary collection of path-connected spaces  there are isomorphisms
there are isomorphisms  for all
for all  .
. is the same thing as a collection of maps
is the same thing as a collection of maps  . Taking
. Taking 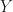 to be
to be 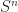 and
and  gives the result.
gives the result. , which is the result for a product of two spaces. The general result then follows by induction.
, which is the result for a product of two spaces. The general result then follows by induction. ,
, ![\psi([f])=([f_1],[f_2])](https://s0.wp.com/latex.php?latex=%5Cpsi%28%5Bf%5D%29%3D%28%5Bf_1%5D%2C%5Bf_2%5D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. ,
,  ,
,  where
where  are the projection maps.
are the projection maps.![\psi ([f]+[g])=\psi([f])+\psi([g])](https://s0.wp.com/latex.php?latex=%5Cpsi+%28%5Bf%5D%2B%5Bg%5D%29%3D%5Cpsi%28%5Bf%5D%29%2B%5Cpsi%28%5Bg%5D%29&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , thus
, thus 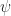 is a homomorphism.
is a homomorphism. ,
, ![\phi([g_1],[g_2])=[g]](https://s0.wp.com/latex.php?latex=%5Cphi%28%5Bg_1%5D%2C%5Bg_2%5D%29%3D%5Bg%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) where
where  ,
,  .
. be a finite real valued measurable function on a measurable set
be a finite real valued measurable function on a measurable set  . Show that the set
. Show that the set  is measurable.
is measurable. . This is popularly known as the graph of a function. Without loss of generality, we may assume that
. This is popularly known as the graph of a function. Without loss of generality, we may assume that  , where we split the function into two nonnegative parts.
, where we split the function into two nonnegative parts. ,
,  .
. , where
, where  indicates outer measure.
indicates outer measure. , where
, where  are disjoint.
are disjoint.
 , we can conclude
, we can conclude  and thus
and thus  is measurable (and has measure zero).
is measurable (and has measure zero).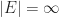 , we partition
, we partition 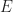 into countable union of sets
into countable union of sets  each with finite measure. By the same analysis, each
each with finite measure. By the same analysis, each  is measurable (and has measure zero). Thus
is measurable (and has measure zero). Thus  is a countable union of measurable sets and thus is measurable (has measure zero).
is a countable union of measurable sets and thus is measurable (has measure zero). , then for any
, then for any  , there exists
, there exists  such that
such that 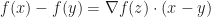 .
.![g:[0,1]\to\mathbb{R}](https://s0.wp.com/latex.php?latex=g%3A%5B0%2C1%5D%5Cto%5Cmathbb%7BR%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) ,
,  . By the Mean Value Theorem for one variable, there exists
. By the Mean Value Theorem for one variable, there exists 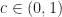 such that
such that  , i.e.
, i.e.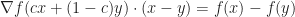 . Here we are using the chain rule for multivariable calculus to get:
. Here we are using the chain rule for multivariable calculus to get: 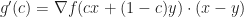 .
.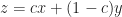 , then
, then  as required.
as required.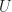 be a non-empty open set in
be a non-empty open set in  . There exists an open interval
. There exists an open interval  containing
containing  . Let
. Let  be the maximal open interval in
be the maximal open interval in  . (The existence of
. (The existence of  and
and  then
then  is an open interval in
is an open interval in  . Upon discarding the “repeated” intervals in the union above, we get that
. Upon discarding the “repeated” intervals in the union above, we get that  be a commutative ring with 1 and
be a commutative ring with 1 and  is an integral domain.
is an integral domain. be ideals of
be ideals of 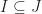 .
.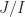 is a prime ideal of
is a prime ideal of  is an integral domain. (
is an integral domain. ( by the Third Isomorphism Theorem. )
by the Third Isomorphism Theorem. )
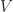 be open subsets of the torus (denoted as
be open subsets of the torus (denoted as  )as shown in the diagram below.
)as shown in the diagram below.  .
.  has
has  as a deformation retract, thus
as a deformation retract, thus  . We note that
. We note that  and
and  , the free product of
, the free product of  and
and  with amalgamation.
with amalgamation.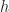 be the generator in
be the generator in  and
and 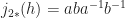 . (
. (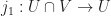 and
and  are the inclusions. )
are the inclusions. )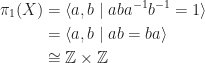

 and
and  , with
, with  . Show that
. Show that 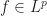 for all
for all 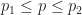 .
. , there exists
, there exists  such that
such that  . This is the key “interpolation step”. Once we have this, everything flows smoothly with the help of Holder’s inequality.
. This is the key “interpolation step”. Once we have this, everything flows smoothly with the help of Holder’s inequality.
 and
and 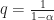 are Holder conjugates, since
are Holder conjugates, since  is easily verified.
is easily verified. , where
, where 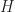 and
and 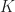 are finite subgroups of a group
are finite subgroups of a group  .
. . However that would be a serious mistake since the conditions for the Second Isomorphism Theorem are not met. In fact
. However that would be a serious mistake since the conditions for the Second Isomorphism Theorem are not met. In fact  may not even be a group.
may not even be a group. .
. . For
. For  , we have:
, we have:
 , i.e. the number of distinct cosets
, i.e. the number of distinct cosets  . Since
. Since  is a subgroup of
is a subgroup of  .
. .
. be a measure space. Let
be a measure space. Let  with
with  , such that
, such that  .
. be a simple function such that
be a simple function such that  .
. . Note that
. Note that  . Hence each nonzero value of
. Hence each nonzero value of 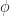 can only be on a set of finite measure. Since
can only be on a set of finite measure. Since 
 . Assume that
. Assume that  has finite order
has finite order  where
where  is an integer.
is an integer. , where
, where  .
. is the least smallest integer such that
is the least smallest integer such that  .
. . Note that
. Note that  is an integer and thus a valid power.
is an integer and thus a valid power. such that
such that  .
. , which leads to
, which leads to  . Note that
. Note that  and
and  are relatively prime.
are relatively prime. , which implies that
, which implies that  which is a contradiction. This proves our result. 🙂
which is a contradiction. This proves our result. 🙂 , the center of the dihedral group
, the center of the dihedral group  ?
?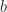 , i.e.
, i.e.  with
with  ,
,  .
.
 .
.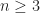 ,
, 
 ,
,  which is abelian. Thus,
which is abelian. Thus, 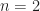 ,
,  , the Klein four-group, which is also abelian. Thus,
, the Klein four-group, which is also abelian. Thus,  ,
,  . Clearly elements in
. Clearly elements in  commute with each other.
commute with each other. ). Let
). Let  be an element in
be an element in  . (
. ( )
)
 , which is only possible if
, which is only possible if  ,
,  )
)
 . Each
. Each  is not in the center since we may consider
is not in the center since we may consider  , i.e.
, i.e.  . Then
. Then  . (since
. (since  also does not commute with
also does not commute with  for the same reason.
for the same reason. ).
). can be defined as the quotient space of
can be defined as the quotient space of  for
for  .
. , we write
, we write ![[x_1, x_2,\dots, x_{n+1}]](https://s0.wp.com/latex.php?latex=%5Bx_1%2C+x_2%2C%5Cdots%2C+x_%7Bn%2B1%7D%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) for the corresponding point in
for the corresponding point in  be the maps defined by
be the maps defined by ![f[x,y]=[x,y,0]](https://s0.wp.com/latex.php?latex=f%5Bx%2Cy%5D%3D%5Bx%2Cy%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and
and ![g[x,y]=[x,-y,0]](https://s0.wp.com/latex.php?latex=g%5Bx%2Cy%5D%3D%5Bx%2C-y%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. ? A common mistake is to try the “straight-homotopy”, e.g.
? A common mistake is to try the “straight-homotopy”, e.g. ![F([x,y],t)=[x,(1-2t)y,0]](https://s0.wp.com/latex.php?latex=F%28%5Bx%2Cy%5D%2Ct%29%3D%5Bx%2C%281-2t%29y%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . This is a mistake as it passes through the point [0,0,0] which is not part of the projective plane.
. This is a mistake as it passes through the point [0,0,0] which is not part of the projective plane. , defined by
, defined by ![\boxed{F([x,y],t)=[x,(\cos\pi t)y, (\sin\pi t)y]}](https://s0.wp.com/latex.php?latex=%5Cboxed%7BF%28%5Bx%2Cy%5D%2Ct%29%3D%5Bx%2C%28%5Ccos%5Cpi+t%29y%2C+%28%5Csin%5Cpi+t%29y%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. , then
, then ![x^2+[(\cos\pi t)y]^2+[(\sin\pi t)y]^2=x^2+y^2=1](https://s0.wp.com/latex.php?latex=x%5E2%2B%5B%28%5Ccos%5Cpi+t%29y%5D%5E2%2B%5B%28%5Csin%5Cpi+t%29y%5D%5E2%3Dx%5E2%2By%5E2%3D1&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
.![F([x,y],0)=[x,y,0]](https://s0.wp.com/latex.php?latex=F%28%5Bx%2Cy%5D%2C0%29%3D%5Bx%2Cy%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
![F([x,y],1)=[x,-y,0]](https://s0.wp.com/latex.php?latex=F%28%5Bx%2Cy%5D%2C1%29%3D%5Bx%2C-y%2C0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
 . This can be quite tedious.
. This can be quite tedious. (Symmetric Difference is Zero). Show that F is measurable.
(Symmetric Difference is Zero). Show that F is measurable. , and
, and  . This in turn (using a lemma that any set with outer measure zero is measurable) implies the measurability of
. This in turn (using a lemma that any set with outer measure zero is measurable) implies the measurability of  and
and  .
. . Using the fact that the collection of measurable sets is a
. Using the fact that the collection of measurable sets is a 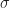 -algebra, we can conclude
-algebra, we can conclude  is measurable.
is measurable. is the union of two measurable sets and thus is measurable.
is the union of two measurable sets and thus is measurable. ,
, 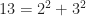 can be expressed as a sum of two squares, while not every prime can be? This is no coincidence, as we will learn from the theorem below.
can be expressed as a sum of two squares, while not every prime can be? This is no coincidence, as we will learn from the theorem below. where a, b are integers if and only if
where a, b are integers if and only if  .
. if a is even, and
if a is even, and 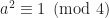 if a is odd. Similar for b. Hence
if a is odd. Similar for b. Hence  .
. for some integer n.
for some integer n. .
. ![(4k)!\equiv [(2k)!]^2\equiv -1\pmod p](https://s0.wp.com/latex.php?latex=%284k%29%21%5Cequiv+%5B%282k%29%21%5D%5E2%5Cequiv+-1%5Cpmod+p&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . We may see this by observing that
. We may see this by observing that  ,
,  , …,
, …,  . Thus
. Thus ![[(2k)!]^2+1\equiv 0\pmod p](https://s0.wp.com/latex.php?latex=%5B%282k%29%21%5D%5E2%2B1%5Cequiv+0%5Cpmod+p&bg=ffffff&fg=1a1a1a&s=0&c=20201002) and hence
and hence 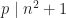 , where
, where  .
.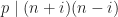 . However
. However 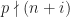 since
since  . Similarly,
. Similarly, 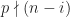 . Therefore
. Therefore  with
with  and
and  .
. 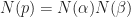 , which means
, which means  . Thus we may conclude
. Thus we may conclude  ,
,  .
.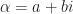 . Then
. Then  and
and  . Prove that if
. Prove that if  in
in  such that if
such that if 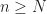 , then
, then  .
.
 as
as 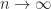 .
. .
. be a finite, non-negative, finitely additive set function on a measurable space
be a finite, non-negative, finitely additive set function on a measurable space  . Show that
. Show that  .
. ,
,  . Then,
. Then, .
. . Then
. Then  implies
implies  .
. be mutually disjoint sets. Define
be mutually disjoint sets. Define  .
. ,
,  .
.  .
.
 be a measure space, and let
be a measure space, and let ![f:X\to [0,\infty]](https://s0.wp.com/latex.php?latex=f%3AX%5Cto+%5B0%2C%5Cinfty%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) be a measurable function. Define the map
be a measurable function. Define the map ![\lambda:\mathcal{M}\to[0,\infty]](https://s0.wp.com/latex.php?latex=%5Clambda%3A%5Cmathcal%7BM%7D%5Cto%5B0%2C%5Cinfty%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) ,
,  , where
, where  denotes the characteristic function of
denotes the characteristic function of 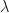 is a measure and that it is absolutely continuous with respect to
is a measure and that it is absolutely continuous with respect to ![g:X\to[0,\infty]](https://s0.wp.com/latex.php?latex=g%3AX%5Cto%5B0%2C%5Cinfty%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , one has
, one has  in
in ![[0,\infty]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cinfty%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. . Let
. Let 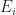 be mutually disjoiint measurable sets.
be mutually disjoiint measurable sets.
 , then
, then  a.e., thus
a.e., thus  . Therefore
. Therefore  .
. ,
,
 be a sequence of simple functions such that
be a sequence of simple functions such that  . Then by the Monotone Convergence Theorem,
. Then by the Monotone Convergence Theorem,  .
. , thus by MCT,
, thus by MCT,  . Note that
. Note that  . Hence,
. Hence,  , and we are done.
, and we are done.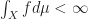 .
. is of
is of 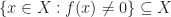 is
is 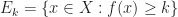 , where
, where  . Denote
. Denote  .
. , and
, and  . (Markov Inequality!)
. (Markov Inequality!)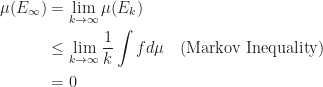
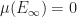 .
. ,
, 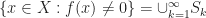
 , and we have expressed the set as a countable union of measurable sets of finite measure.
, and we have expressed the set as a countable union of measurable sets of finite measure. be a measurable function with
be a measurable function with  . Show that for any
. Show that for any  such that for any measurable set
such that for any measurable set  , we have
, we have  .
.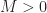 , we define
, we define  , for all
, for all 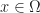 .
. .
. . Then for any
. Then for any  ,
,
 . By Monotone Convergence Theorem,
. By Monotone Convergence Theorem, .
. .
. .
.

 be a composition series of
be a composition series of 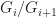 is simple.
is simple. and
and  are solvable (every subgroup of a solvable group is solvable), the quotient
are solvable (every subgroup of a solvable group is solvable), the quotient  , by the fact that the factor is simple, we have
, by the fact that the factor is simple, we have 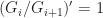 or
or  , then this contradicts the fact that
, then this contradicts the fact that  for some prime
for some prime  .
. , so we have that
, so we have that  . By induction,
. By induction,  .
. . Thus G is finite.
. Thus G is finite. . We want to find the number of conjugacy classes of G.
. We want to find the number of conjugacy classes of G. . Since
. Since  , by Lagrange’s Theorem,
, by Lagrange’s Theorem,  .
. . We are done.
. We are done. . Then
. Then  . Thus
. Thus  is cyclic which implies that G is abelian. (contradiction).
is cyclic which implies that G is abelian. (contradiction). . This means that the entire group G is abelian. (contradiction).
. This means that the entire group G is abelian. (contradiction). be the distinct conjugacy classes of G.
be the distinct conjugacy classes of G. , where
, where  .
.![\displaystyle p^3=|G|=\sum_{i=1}^n [G:C_G(x_i)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%5E3%3D%7CG%7C%3D%5Csum_%7Bi%3D1%7D%5En+%5BG%3AC_G%28x_i%29%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. , then
, then  , which means
, which means ![[G:C_G(x_i)]=1](https://s0.wp.com/latex.php?latex=%5BG%3AC_G%28x_i%29%5D%3D1&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. , then
, then  . Since
. Since  , thus
, thus  . Thus we have
. Thus we have  . Since
. Since  is a subgroup of
is a subgroup of  . Thus
. Thus ![[G:C_G(x_i)]=p^3/p^2=p](https://s0.wp.com/latex.php?latex=%5BG%3AC_G%28x_i%29%5D%3Dp%5E3%2Fp%5E2%3Dp&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. , which leads us to
, which leads us to  .
.

 of index
of index  ,
, 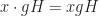 .
. .
. . If
. If  , then
, then  for all
for all  . In particular when g=1, xH=H, i.e.
. In particular when g=1, xH=H, i.e.  .
. . In particular,
. In particular,  , since
, since  is a normal subgroup of
is a normal subgroup of 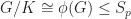 . Thus
. Thus  .
. . Note that
. Note that  since
since ![|G/K|=[G:H][H:K]=p[H:K]\geq p](https://s0.wp.com/latex.php?latex=%7CG%2FK%7C%3D%5BG%3AH%5D%5BH%3AK%5D%3Dp%5BH%3AK%5D%5Cgeq+p&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. be a prime divisor of
be a prime divisor of  . Then
. Then 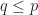 since
since  . Since
. Since  ,
,  . Therefore,
. Therefore, 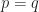 , i.e.
, i.e.  .
.![p=p[H:K] \implies [H:K]=1](https://s0.wp.com/latex.php?latex=p%3Dp%5BH%3AK%5D+%5Cimplies+%5BH%3AK%5D%3D1&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , i.e. H=K. Thus, H is normal in G.
, i.e. H=K. Thus, H is normal in G. .
. . Note that the tricky part is that
. Note that the tricky part is that  is not actually the usual {0,1}, but rather {0,3} (considered as part of
is not actually the usual {0,1}, but rather {0,3} (considered as part of  ). Hence the elements of
). Hence the elements of  are {0,3}, {1, 4}, {2, 5}, which can be seen to be isomorphic to
are {0,3}, {1, 4}, {2, 5}, which can be seen to be isomorphic to  .
. , where
, where  , defined by
, defined by  .
. , then
, then  , and thus
, and thus  .
.
 , and surjectivity is quite clear too.
, and surjectivity is quite clear too.
 be a sequence satisfying
be a sequence satisfying 
 , and also
, and also  .
. converges uniformly on A (to a function f).
converges uniformly on A (to a function f). .
.  such that
such that  implies
implies  .
. ,
,
 converges uniformly.
converges uniformly.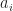 are of the same sign (e.g. all positive or all negative).
are of the same sign (e.g. all positive or all negative).
 converges uniformly on [0,1] and thus
converges uniformly on [0,1] and thus  .
. , also known as
, also known as  (easier to type).
(easier to type). by
by  .
.

 .
. .
. .
. is trivial.
is trivial. . Consider
. Consider  ,
,  ,
,  , …,
, …,  .
.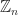 .
. . This is because
. This is because  . Hence if
. Hence if  , then
, then  , which implies that
, which implies that  which implies that
which implies that  .
. and thus we may take
and thus we may take 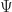 is surjective.
is surjective.



 and measures should be additive over disjoint sets in X.
and measures should be additive over disjoint sets in X.
 for all
for all 
 is any disjoint sequence (
is any disjoint sequence ( ) of sets in X, then
) of sets in X, then .
.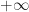 , we say it is finite. More generally, if there exists a sequence
, we say it is finite. More generally, if there exists a sequence  and such that
and such that  for all n, then we say that
for all n, then we say that  be definied on X by
be definied on X by  , for all
, for all  . We can see that
. We can see that  be defined by
be defined by  ,
,  if
if  .
.  . This measure is usually called Lebesgue measure (or sometimes Borel measure). It is not a finite measure since
. This measure is usually called Lebesgue measure (or sometimes Borel measure). It is not a finite measure since  . But it is
. But it is  ) such that
) such that  for all n.
for all n.
 ) in M(X,X) such that:
) in M(X,X) such that: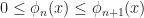 for
for  .
.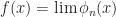 for each
for each  .
.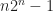 , let
, let 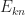 be the set
be the set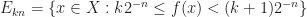 .
. , let
, let  .
.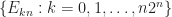 are disjoint.
are disjoint. on
on  is true.
is true. , i.e.
, i.e.  , thus
, thus  for each
for each 



 and transform the 100 tuple
and transform the 100 tuple  into the 100 tuple
into the 100 tuple  if
if  is an even number. We say that a permutation
is an even number. We say that a permutation 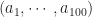 of
of  is good if starting from
is good if starting from 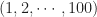 one can obtain it after finite number of steps. Find the total number of distinct good permutations of
one can obtain it after finite number of steps. Find the total number of distinct good permutations of 

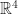 , what are the possible dimensions of the subspace
, what are the possible dimensions of the subspace  ?
?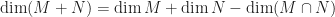
 .
.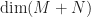 , the
, the 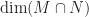 can take the values of 0, 1, or 2.
can take the values of 0, 1, or 2.


 , how do we find the (shortest) distance of a plane to the origin?
, how do we find the (shortest) distance of a plane to the origin?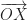 must be perpendicular to the plane, i.e. parallel to the normal vector
must be perpendicular to the plane, i.e. parallel to the normal vector  .
.

 ,
, 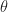 is either 0 or 180 degrees, hence
is either 0 or 180 degrees, hence 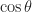 is either 1 or -1.
is either 1 or -1. .
.