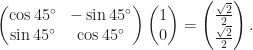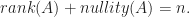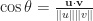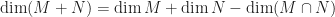Diagonalizable & Minimal Polynomial
A matrix or linear map is diagonalizable over the field 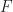
Characteristic Polynomial
Let 
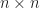


Cayley-Hamilton Theorem
Every square matrix over a commutative ring satisfies its own characteristic equation:
If 


A matrix or linear map is diagonalizable over the field
Let
Every square matrix over a commutative ring satisfies its own characteristic equation:
If
If 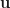
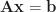
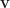

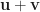

Proof:
1)
2)
3)
4)
Characteristic Polynomial,
Eigenspace
The solution space of 

Sum/Product of Eigenvalues
– The sum of all eigenvalues of 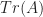
– The product of all eigenvalues of 
Rotation Matrix
The rotation matrix
rotates points in the 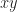
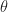
For example rotating the vector 
Finding Least Squares Solution
Given 

Projection
If we know a least squares solution 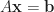

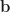
Dimension Theorem for Matrices (Also known as Rank-Nullity Theorem)
If 
(

Linear Independence and the Wronskian
A set of vector functions 
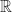
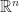
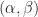
![\displaystyle W[\vec{f_1}(x),\dots,\vec{f_n}(x)]\neq 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+W%5B%5Cvec%7Bf_1%7D%28x%29%2C%5Cdots%2C%5Cvec%7Bf_n%7D%28x%29%5D%5Cneq+0&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

Dot Product
–
–
Span

Subspaces
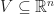
1) 
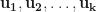
2) 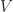
(i) for all 

(ii) for all 

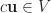
3)
(Sufficient to check either one of Condition 1, 2, 3.)
Remark:
For 


Linear Independence and Dependence
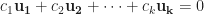
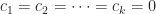
If the system has non-trivial solutions, i.e. at least one 
Row echelon form (REF)
For each non-zero row, the leading entry is to the right of the leading entry of the row above.
E.g.
Note that the leading entry 9 of the second row is to the right of the leading entry 1 of the first row.
Reduced row echelon form (RREF)
A row echelon form is said to be reduced, if in each of its pivot columns, the leading entry is 1 and all other entries are 0.
E.g.
Elementary Row Operations
1) 

2) 
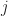
3) 

Gaussian Elimination Summary
Gaussian Elimination is essentially using the elementary row operations (in any order) to make the matrix to row echelon form.
Gauss-Jordan Elimination
After reaching row echelon form, continue to use elementary row operations to make the matrix to reduced row echelon form.
This is an interesting question on vector subspaces (a topic from linear algebra):
Question:
If V and W are 2-dimensional subspaces of 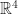

(A) 1 only
(B) 2 only
(C) 0 and 1 only
(D) 0, 1, and 2 only
(E) 0, 1, 2, 3, and 4
To begin this question, we would need this theorem on the dimension of sum and intersection of subspaces (for finite dimensional subspaces):
Note that this looks familiar to the Inclusion-Exclusion principle, which is indeed used in the proof.
Hence, we have 
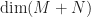
Thus, 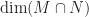
Answer: Option D
If you are looking for a lighthearted introduction on linear algebra, do check out Linear Algebra For Dummies. Like all “For Dummies” book, it is not overly abstract, rather it presents Linear Algebra in a fun way that is accessible to anyone with just a high school math background. Linear Algebra is highly useful, and it is the tool that Larry Page and Sergey Brin used to make Google, one of the most successful companies on the planet.
Thanks for reading our blog Mathtuition88.com.
We are also on:
Facebook: https://www.facebook.com/mathtuition88
Twitter: https://twitter.com/mathtuition88
Google+: Mathtuition88
If you are a subscriber, thanks for your support! We will continue our mission of blogging interesting articles on Mathematics!
Featured book:
Coding the Matrix: Linear Algebra through Applications to Computer Science
Google’s signature ranking algorithm “PageRank” is heavily based on linear algebra! Read the above book to find out more!
An engaging introduction to vectors and matrices and the algorithms that operate on them, intended for the student who knows how to program. Mathematical concepts and computational problems are motivated by applications in computer science. The reader learns by doing, writing programs to implement the mathematical concepts and using them to carry out tasks and explore the applications. Examples include: error-correcting codes, transformations in graphics, face detection, encryption and secret-sharing, integer factoring, removing perspective from an image, PageRank (Google’s ranking algorithm), and cancer detection from cell features. A companion web site,
codingthematrix.com
provides data and support code. Most of the assignments can be auto-graded online. Over two hundred illustrations, including a selection of relevant xkcd comics.
Chapters: The Function, The Field, The Vector, The Vector Space, The Matrix, The Basis,Dimension, Gaussian Elimination, The Inner Product, Special Bases, The Singular Value Decomposition, The Eigenvector, The Linear Program
Source: http://www.math.columbia.edu/~bayer/LinearAlgebra/pdf/inverse.pdf
Backup copy (In case of broken link): 3×3 Matrix Inverse
This is an excellent method for finding the inverse of a 3×3 matrix, probably the fastest and easiest method for 3×3.
(Row reduction is better for 4×4 matrices and above.)
This method was first introduced to me by my student!
Featured book:
Linear Algebra and Its Applications, 4th Edition
1) https://www.math.okstate.edu/~binegar/3013-S99/3013-l16.pdf
(How to diagonalize matrices)
2) http://www.sosmath.com/matrix/expo/expo.html
(How to find exponential of matrices)
3) http://en.wikipedia.org/wiki/Matrix_differential_equation
(Matrix Differential Equations)
4) http://www.ucl.ac.uk/CNDA/courses/coursework/JNF.pdf
(Jordan Normal Form)
5) http://www.math.niu.edu/~fletcher/jnf.pdf
(Jordan Normal Form for 2×2 Matrices)
6) http://www.math.colostate.edu/~gerhard/M345/CHP/ch9_6.pdf
(Matrix Exponential with repeated Eigenvalues)
7) http://www.math.vt.edu/people/afkhamis/class_home/notes/F08W12.pdf
(Matrix Differential equation with repeated Eigenvalues)
8) http://www.math.utah.edu/~gustafso/2250matrixexponential.pdf
(Matrix Exponential of Block Diagonal)
Featured book:
Linear Algebra and Its Applications, 4th Edition
Linear algebra is relatively easy for students during the early stages of the course, when the material is presented in a familiar, concrete setting. But when abstract concepts are introduced, students often hit a brick wall. Instructors seem to agree that certain concepts (such as linear independence, spanning, subspace, vector space, and linear transformations), are not easily understood, and require time to assimilate. Since they are fundamental to the study of linear algebra, students’ understanding of these concepts is vital to their mastery of the subject. David Lay introduces these concepts early in a familiar, concrete Rn setting, develops them gradually, and returns to them again and again throughout the text so that when discussed in the abstract, these concepts are more accessible.